

排序服务
排序
排序节点使交易有序,并与其他排序节点一起形成一个排序服务。
本不会像其他分布式的以及无需许可的区块链中那样产生分叉。
排序节点还将链码执行的背书(发生在节点)与排序分离。
排序节点和通道配置
排序节点还维护着允许创建通道的组织列表。
列表本身保存在“排序节点系统通道”(也称为“排序系统通道”)的配置中。
排序节点还对通道执行基本访问控制,限制谁可以读写数据,以及谁可以配置数据。
谁有权修改通道中的配置元素取决于相关管理员在创建联盟或通道时设置的策略。
排序节点和身份
节点、应用程序、管理员和排序节点,都从它们的数字证书和成员服务提供者(MSP)定义中获取它们的组织身份。
与 Peer 节点一样,排序节点属于组织。也应该像 Peer 节点一样为每个组织使用单独的证书授权中心(CA)。
排序节点与交易流程
提案
客户端应用程序将交易提案发送给一组节点
节点将调用智能合约来生成一个账本更新提案,然后背书该结果。
背书节点将向客户端应用程序返回一个提案响应。
打包
应用程序客户端把包含已背书交易提案响应的交易提交到排序服务节点。
排序服务创建交易区块,这些交易区块最终将分发给通道上的所有 Peer 节点
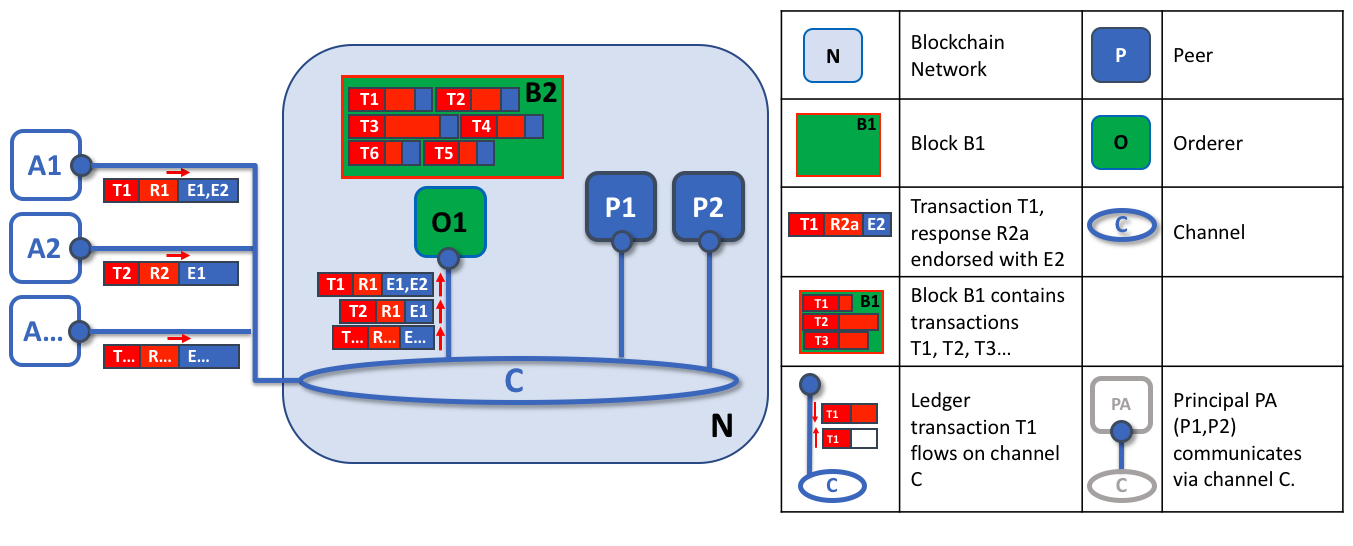
排序节点的第一个角色是打包提案的账本更新。
一个区块中交易的顺序不一定与排序服务接收的顺序相同,因为可能有多个排序服务节点几乎同时接收交易。
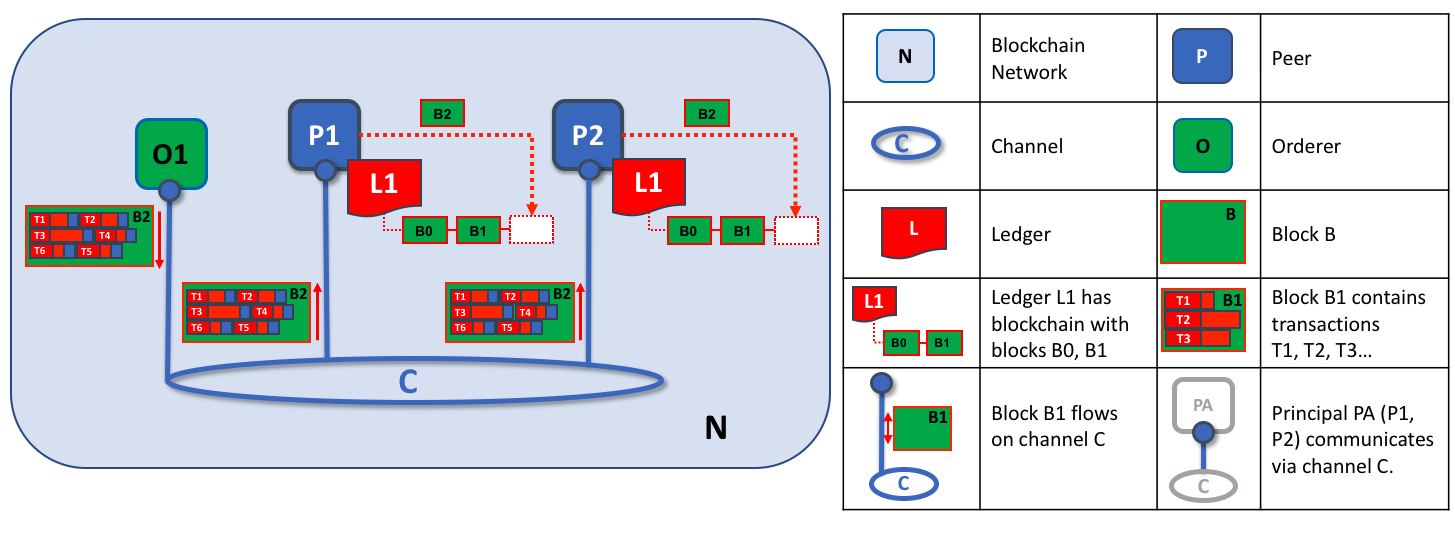
在 Hyperledger Fabric 中,由排序服务生成的区块是最终的。一旦一笔交易被写进一个区块,它在账本中的地位就得到了保证。
Hyperledger Fabric 的最终性意味着没有账本分叉,也就是说,经过验证的交易永远不会被重写或删除。
验证和提交
每个节点将独立地以确定的方式验证区块,以确保账本保持一致。
无效的交易仍然保留在排序节点创建的区块中,但是节点将它们标记为无效,并且不更新账本的状态。
排序服务的实现
几种不同的实现可以在排序服务节点之间就严格的交易排序达成共识。
Raft (推荐)
作为 v1.4.1 的新特性,Raft 是一种基于
etcd中 Raft 协议实现的崩溃容错(Crash Fault Tolerant,CFT)排序服务。Raft 遵循“领导者跟随者”模型,这个模型中,在每个通道上选举领导者节点,其决策被跟随者复制。Raft 排序服务会比基于 Kafka 的排序服务更容易设置和管理,它的设计允许不同的组织为分布式排序服务贡献节点。
Raft
Fabric 实现了使用“领导者跟随者”模型的 Raft 协议,领导者是在一个通道的排序节点中动态选择的(这个集合的节点称为“共识者集合(consenter set)”),领导者将信息复制到跟随者节点。
Raft 被称为“崩溃容错”是因为系统可以承受节点的损失,包括领导者节点,前提是要剩余大量的排序节点(称为“法定人数(quorum)”)。
使用 Raft,所有内容都会嵌入到您的排序节点中。Raft 更容易设置。
使用 Raft,每个组织都可以有自己的排序节点参与排序服务,从而形成一个更加分散的系统。
Raft 是原生支持的,Raft 允许用户指定哪个排序节点要部署到哪个通道。
Raft 是向开发拜占庭容错(BFT)排序服务迈出的第一步。
日志条目(Log entry)
Raft 排序服务中的主要工作单元是一个“日志条目”,该项的完整序列称为“日志”。
大多数成员(换句话说是一个法定人数)同意条目及其顺序,则我们认为条目是一致的,然后将日志复制到不同排序节点上。
共识者集合(Consenter set)
主动参与给定通道的共识机制并接收该通道的日志副本的排序节点。
有限状态机(Finite-State Machine,FSM)
Raft 中的每个排序节点都有一个 FSM,它们共同用于确保各个排序节点中的日志序列是确定(以相同的顺序编写)。
法定人数(Quorum)
描述需要确认提案的最小同意人数。
对于每个共识者集合,这是大多数节点。
领导者
通道的共识者集合都选择一个节点作为领导者,领导者负责接收新的日志条目,将它们复制到跟随者的排序节点,并在认为提交了某个条目时进行管理。
跟随者
跟随者从领导者那里接收日志并复制它们,确保日志保持一致。
交易中的Raft
在 Raft 中,交易(以提案或配置更新的形式)由接收交易的排序节点自动路由到该通道的当前领导者。
架构说明
Raft 是如何选举领导者
节点总是处于以下三种状态之一:跟随者、候选人或领导者。
所有节点最初都是作为跟随者开始的。
在一段时间内没有接收到日志条目或心跳(例如,5秒),节点将自己提升到候选状态。
在候选状态中,节点从其他节点请求选票。如果候选人获得法定人数的选票,那么他就被提升为领导者。
快照
Raft 使用了一个称为“快照”的过程,在这个过程中,用户可以定义日志中要保留多少字节的数据。这个数据量将决定区块的数量。
快照中只存储完整的区块



